
Цифры и буквы для табличек № 0850W (пустое поле, тип «C») 0892W
- EN
- DE
- IT
- ES
- FR
- RU
- SK
- PL
| Добавить в закладки | данные BIM | Артикул | Название | Номинальная ширина | Ступень давления | Вес |
|---|---|---|---|---|---|---|
| 5015308 | 40 MM | 0,01 KG |
Эти продукты, возможно, также заинтересуют вас:
0882H
Цифры и буквы для табличек № 0870W (пустое поле, тип «C»)
0882W
Цифры и буквы для табличек № 0850W (тип «C»)
0892H
Цифры и буквы для табличек № 0870W (пустое поле, тип «C»)
Назад к обзору
Этот продукт в Вашей стране не был найден
Аналогичные продукты Вы найдете в категории
«Как же так? — спросите вы. В древнегреческом письме буквы обозначали числа, эту особенность создатели славянской азбуки перенесли в свою систему, как и многое другое, при этом славянские буквы повторили числовое значение греческих букв. Но греческий язык не похож на славянский, поэтому в азбуку пришлось добавить новые буквы для славянских звуков, вот они-то и не имели числового значения. Как в то время различали буквы и цифры? Если буква была буквой, к ней ничего не приписывали, но если буква была цифрой, над ней ставили знак — титло, а по бокам на середине высоты буквы — точки. Представляете, как трудно было тогда учиться математике?! Это вы ещё других чисел не видели! Числа второго десятка (от 11 до 19) записывались так: сначала единицы, потом десятки: ·аi҃· — 11, ·иi҃· — 18. В других двузначных числах сначала шли десятки, потом — единицы; ·ка҃· — 21, ·оа҃· — 71. Кстати, такой порядок единиц и десятков поддержан русскими числительными: семнадцать (буквально: семь на десяти), т.е. единицы + десятки; двадцать пять или сорок девять — наоборот, десятки + единицы. А вот трёхзначное число: ·тsϵ҃· — 365. Для четырёхзначных использовались дополнительные символы: ·д҃· — это 4, а ·҂д҃· — это 4000; ·҂sф҃ла· — 6531. Получается, при счёте и вычислениях запись не помогала, как нам сейчас. Смотрите: вот 15 — ·ϵi҃·, а вот 51 — ·на҃·; для нас 300 + 600 = 900, как 3 + 6 = 9, а когда-то ·т҃· + ·х҃· = ·ц҃· вовсе не поддерживалось выражением ·г҃· + ·s҃· = ·ѳ҃·. Да, древнерусская математика была сложнее современной! И всё же люди успешно считали в своей практической деятельности и при необходимости оперировали большими числами — миллионами и миллиардами, придумали для них оригинальные символы: ҈ — для сотен тысяч (легион), ҉ — для миллионов (леодр), и внутри писалась буква-цифра. Вся эта сложная система была отменена реформой Петра I в 1708 — 1710 гг., когда в России начали развиваться точные науки, понадобились математические расчёты и люди, способные их делать. Тогда же и были введены арабские цифры, а история букв-цифр на этом закончилась. Все материалы рубрики «Говорите по-русски»
Елена Филинкова, Вернуться на главную страницу
|
 — Ведь это совсем разные вещи!» Конечно, разные, однако буквы были и есть и настолько значимы, что могли брать на себя и роль цифр.
— Ведь это совсем разные вещи!» Конечно, разные, однако буквы были и есть и настолько значимы, что могли брать на себя и роль цифр. Выглядело примерно так: ·а҃· — 1, ·к҃· — 20, ·т҃· — 300.
Выглядело примерно так: ·а҃· — 1, ·к҃· — 20, ·т҃· — 300.
— преобразование букв в цифры — python
спросил
Изменено 2 года, 3 месяца назад
Просмотрено 1к раз
сообщение = ул(ввод()) для меня в сообщении: если я == "а": я = 1 если я == "б": я = 2 печать (я)
т. д.
Я пытаюсь создать генератор кода, в котором пользователь вводит строку, например. «привет», и он преобразуется в числовой код путем присвоения каждой букве номера в зависимости от их положения в алфавите. 1 = а, 2 = б и так далее. Метод, который я использую в настоящее время, очень длинный — есть ли другие способы сделать это, чтобы избежать этих проблем?
д.
Я пытаюсь создать генератор кода, в котором пользователь вводит строку, например. «привет», и он преобразуется в числовой код путем присвоения каждой букве номера в зависимости от их положения в алфавите. 1 = а, 2 = б и так далее. Метод, который я использую в настоящее время, очень длинный — есть ли другие способы сделать это, чтобы избежать этих проблем?
Как я могу напечатать ответ вместе, чтобы числа не были в нескольких строках, например. 1 2 3 21 19
- python
- строка
- цикл for
- оператор if
- ввод
Использовать строку lib:
строка импорта [string.ascii_lowercase.index(s)+1 для s в 'hello'.lower()]
Вывод:
[8, 5, 12, 12, 15]
Вы можете преобразовать букву в ее кодовое значение ASCII, вычислить ее позицию, затем добавить позицию буквы в строку и распечатать строку.
Чтобы получить числовое значение символа, используйте ord() , чтобы получить символ из числового значения, используйте метод char() .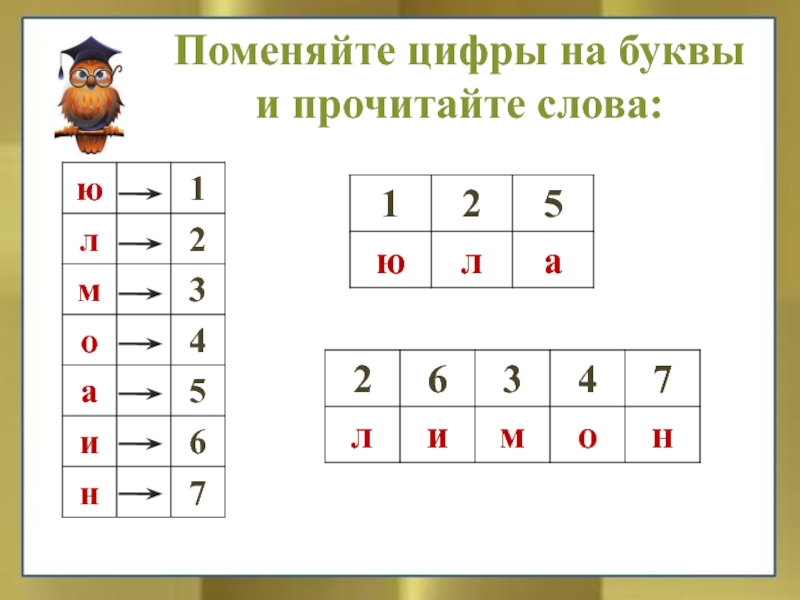
Ссылка на таблицу ASCII
строка импорта low_letter = список (string.ascii_lowercase)
теперь у вас есть список всех букв по порядку
так что…
message = str(input())
для меня в сообщении:
печать (low_letter.index (я))
теперь у вас есть индекс
и если вам нужен верхний регистр:
upper_case = list(string.ascii_uppercase)
```
сообщение = строка (ввод ())
для char в msg:
print(ord(char) - ord('a') + 1)
Идея состоит в том, чтобы преобразовать каждый символ в ASCII, используя ord() в python, и вычесть его с помощью ASCII из «a» и + 1.
Итак, рассмотрим строку «hello»:
Вывод будет:
привет
8
5
12
12
15
Примечание. Здесь мы вычитаем ASCII символа из ASCII символа «a», чтобы получить правильную позицию в алфавитном порядке.
Например: ч
Ascii h = 104
Ascii = 97
Таким образом, наш требуемый ответ = Ascii of h - Ascii of a + 1
= 104 - 97 + 1 = 8
И если мы посмотрим в алфавитном порядке - a,b,c,d,e,f,g,h -> h это 8-й символ
Надеюсь, это поможет вам. Спасибо
Спасибо
1Просто создайте словарь, который сопоставляет «a» с 1, «b» с 2 и т. д.
из строки import ascii_lowercase отображение = dict (zip (ascii_lowercase, диапазон (1, 27)))
И используйте это так:
numbers = [mapping[char] для char в сообщении, если char в сопоставлении]
Вам нужно проверить, есть ли каждый символ в алфавите, иначе вы получите ошибку. Если вы также хотите закрыть прописные буквы, измените сообщение до message.lower() в строке цикла.
Использование index() Каждая итерация неэффективна, хотя в данном случае это не имеет большого значения, поскольку вы просматриваете не более 26 букв. Но в целом это не очень хорошая стратегия. Поиск по словарю — O(1).
р — Преобразование букв в числа
У меня есть куча букв, и я не могу понять, как преобразовать их в их числовой эквивалент.
букв[1:4]
Есть ли функция
цифры ['e']
который возвращает
5
или что-то определенное пользователем (т. е. 1994)?
е. 1994)?
Я хочу преобразовать все 26 букв в определенное значение.
Я не знаю «предустановленной» функции, но такое сопоставление довольно легко настроить, используя match . Для конкретного примера, который вы приводите, сопоставляя букву с ее позицией в алфавите, мы можем использовать следующий код:
myLetters <- Letters[1:26]
совпадение("а", мои буквы)
[1] 1
Почти так же легко связать другие значения с буквами. Ниже приведен пример использования случайного выбора целых чисел.
# присваиваем значения каждой букве, здесь выборка от 1 до 2000 set.seed(1234) myValues <- образец (1: 2000, размер = 26) имена (мои значения) <- мои буквы мои значения [соответствие («а», имена (мои значения))] а 228
Также обратите внимание, что этот метод можно распространить и на упорядоченные наборы букв (строк).
1 Функция и здесь кажется уместной.
который (буквы == 'e') #[1] 52
Вы можете попробовать эту функцию:
letter2number <- function(x) {utf8ToInt(x) - utf8ToInt("a") + 1L}
Вот краткий тест:
буква2число("e")
#[1] 5
сет. сид(123)
мои буквы <- буквы [образец (26,8)]
#[1] "h" "t" "j" "u" "w" "a" "k" "q"
unname(sapply(myletters, letter2number))
#[1] 8 20 10 21 23 1 11 17
сид(123)
мои буквы <- буквы [образец (26,8)]
#[1] "h" "t" "j" "u" "w" "a" "k" "q"
unname(sapply(myletters, letter2number))
#[1] 8 20 10 21 23 1 11 17
Функция вычисляет код utf8 буквы, на которую она передается, вычитает из этого значения код utf8 буквы «а» и добавляет к этому значению число один для обеспечения соблюдения соглашения об индексации R, в соответствии с которым нумерация букв начинается с 1, а не с 0.
Код работает, потому что числовая последовательность кодов utf8, представляющих буквы, соответствует алфавитному порядку.
Для заглавных букв можно использовать, соответственно,
LETTER2num <- function(x) {utf8ToInt(x) - utf8ToInt("A") + 1L}
1Создайте вектор поиска и используйте простое подмножество:
x <- letter[1:4] поиск <- setNames(seq_along(буквы), буквы) поиск[x] #а б в г #1 2 3 4
Используйте unname , если вы хотите удалить имена.
спасибо за все идеи, но я тупица.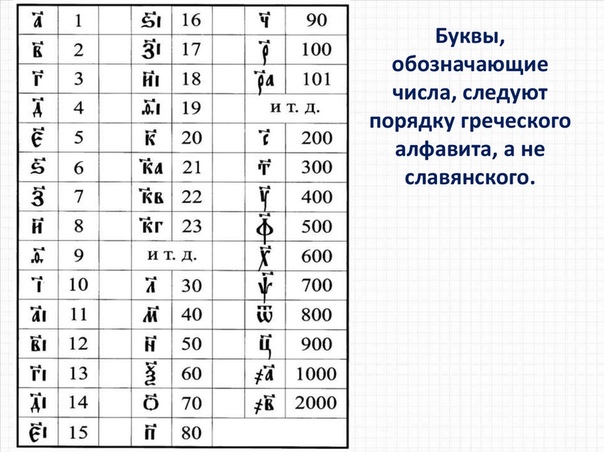
Вот что я сделал. Сделал сопоставление каждой буквы с определенным числом, затем назвал каждую букву
df=data.frame(L=letters[1:26],N=rnorm(26)) дф[дф$L=='е',2]1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.